Reflections on Creating an API Program
More than two years ago, IPUMS launched an ambitious plan to create an API Program and make IPUMS data available programmatically via API. Today, IPUMS is thrilled to announce that our IPUMS NHGIS Metadata and Data Extract APIs are leaving beta and reaching the v1.0 milestone! This marks the first time that IPUMS data has ever been publicly available programmatically via a non-beta API.
As we reach this important milestone, this is a great time to look back and reflect on our API journey as an organization. This post will take a look at some of the challenges we encountered as we built an API Program from scratch, and some of the decisions that helped get us here today.
Creating an API Habit
As an organization we had not focused on building APIs previously, so we knew we would need to think about how to make space for this new sort of work. Very early on, we formed what we eventually called the API Program Support Team (APST), comprised half of developers and half of researchers (our equivalent of the “business” folks) and chaired by the IT Director (who straddles both worlds). This new team created a space where we could begin to tackle some of the most fundamental business and technical questions, such as developing an API roadmap aligned with our business goals, defining the minimum infrastructure we needed to begin developing and publishing APIs, establishing the metrics by which we would measure our API Program’s success, and fostering API development best practices and standards across our development teams.
Perhaps the one thing we were focused on more than anything else was the creation of an “APIs as First-Class Products” mindset. We knew that to be successful APIs could not be viewed as a technical concern or an internal IT project. Rather, they had to be seen as products in their own right, a means towards novel ways of growing our mission (which in our case is getting more of our data into the hands of more users and new types of users). Stakeholder buy-in was an important task for us from the beginning, so in those early days we held focus groups and interest meetings to begin the long process of pivoting towards an API-minded organization.
 An early stakeholder presentation
An early stakeholder presentation
For the past two years, the APST has worked to educate the organization on APIs and their benefits, to gather stakeholder perspective and priorities, and to assist development teams as our initial APIs have been built out. The APST is also the group in charge of overarching API Program tasks such as measuring key success metrics and providing the shared infrastructure and scaffolding needed to support our API Program, such as managing the API gateway and developer documentation services and developing an API styleguide for our developers.
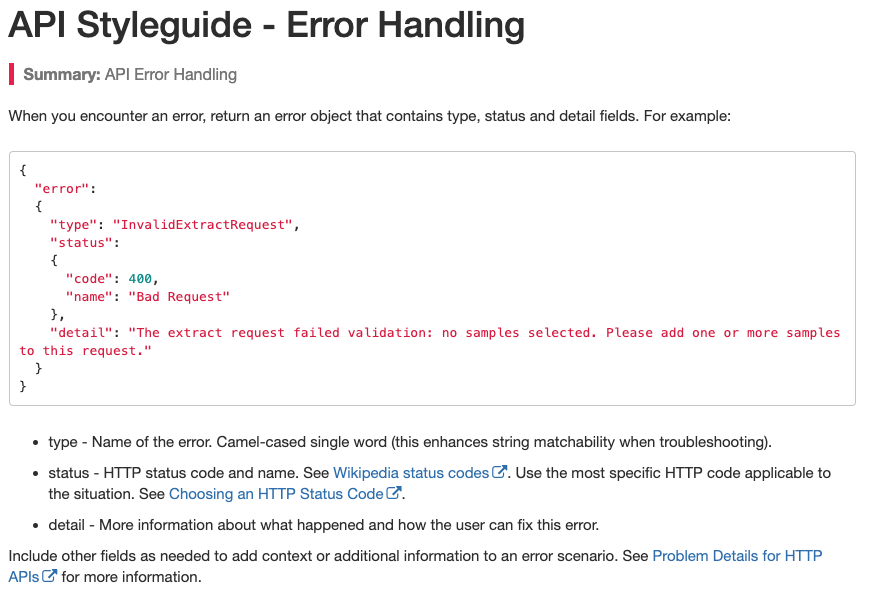 Example page from our internal API Styleguide
Example page from our internal API Styleguide
A final key thing we did in the early going was to recognize that we were not experts and that we would benefit from bringing in an outside perspective. Over the past two years, we’ve had multiple visits from an API consultant who has helped us with everything from refining our API vision to effective stakeholder communications to the nuts and bolts of how best to actually design and build these APIs.
One API or Many?
One of the big design challenges we hit early on is whether to conceptualize our API offering as one unified IPUMS API or a series of distinct APIs. A unified API would be conceptually clean for our end users, but the reality is that we serve up a wide variety of data that differs in scale, structure, and organization. Wedging these all into a single API would be cumbersome at best.
Where we landed was something of a compromise - we have multiple APIs, but with a design principle that similar APIs should behave similarly. For example, we will have a Microdata Data Extract API and an NHGIS Data Extract API, and for those APIs the endpoints and HTTP verbs will be the same where possible, even though the payloads will necessarily be different due to data structure differences. As one example, IPUMS NHGIS data is organized by table, while IPUMS USA data is organized by variable, so the vocabulary of the payloads will differ to reflect that. A similar story will be the case for our Metadata APIs and eventually our Data Streaming APIs, as well.
We strive to standardize as much as possible, and we considered things like URL design very carefully to design a scheme that will be consistent yet flexible enough to adapt to all of our products. As we’re still early in the process, we don’t yet know how successful we ultimately were, but we’re hopeful!
Our Data Model is Not Obvious
A second design challenge we encountered is how to communicate our data model to our users so that they could assemble data requests. Unlike more ubiquitous domains such as e-commerce or photo collections or social media messages, the structure and even the vocabulary of the IPUMS data model is not widely understood and can be challenging to comprehend. IPUMS data involves some pretty specific demographic and internal-to-IPUMS concepts such as variable and dataset groups, NHGIS codes, breakdown values, extents, universes… the list goes on. How do we make our data model accessible and intuitive for our users, particularly for new non-traditional user groups such as data journalists?
 So many options! How to make this intuitive via API?
So many options! How to make this intuitive via API?
On our websites we have the ability to provide lots of context and interface elements to help users understand the choices they are making as they browse and assemble a data request. We don’t have those same opportunities with the API, so we had to think carefully about request payload design. In some cases, we changed the names of concepts to make more sense for external users. In other cases, we simply tried to write really good developer documentation and code samples.
When operating in a niche space like we are with the diversity of data we are trying to provide, it’s probably unrealistic to expect that our API will be as intuitive to use as a more mainstream or narrowly scoped API. Nevertheless, we have put a lot of energy into making the API as intuitive and usable as we can, given these constraints.
Real-Time Streaming of IPUMS Data is Hard
The final major design challenge we had in our early API efforts was whether to aim for real-time streaming of data back to the users right from the get-go, which is the most intriguing target in terms of unlocking new models of IPUMS data dissemination. Real-time data streaming would present some quite difficult technical challenges - it’s not uncommon for IPUMS users to make data requests on the order of 10, 20 or more gigabytes, and for our more popular products we currently have queue wait times that occasionally stretch to an hour or more. We would have to tackle these challenges if we were going to offer up an API that provided real-time data streaming. We weren’t sure we wanted to go that way with our first API - we were more comfortable doing something a bit smaller in scale.
We compromised by building our Data Extract APIs first. In this API, the user does not get data in real-time, but rather submits an extract request to be enqueued alongside the extract requests coming in from our websites. We then outfitted the API with a status endpoint so that users can check the status of their requests. When the extract is complete, users can use the API to retrieve the data extract zip file, and then can programmatically unpack it and operate on the data as needed.
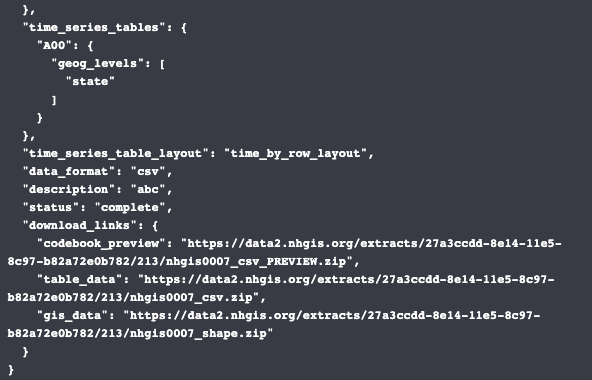 ‘status’ is complete, can now download zip file
‘status’ is complete, can now download zip file
We recognize that this might be an awkward model for interacting with IPUMS data programmatically as there is now added delay and code complexity for the user as they must check on the request status and then download and deal with the zip file. However, the ability to provide this solution to users relatively quickly versus the real-time data streaming option tipped our API roadmap towards this approach. We still intend to provide real-time data streaming APIs in the future, and have already begun early work towards that goal, but in the meantime there are many users and use cases that can benefit from the current solution.
Conclusion: Don’t Let Perfect be the Enemy of Good
Our API journey thus far can probably be summed up this way: don’t let perfect be the enemy of good. Compromise and pragmatism have been important principles for our success thus far. Building an IPUMS API Program, especially as an organization with no prior API development history, felt like a hugely daunting task two years ago. By putting in place good support structures and figuring out how to make incremental progress and release value to our users as quickly as possible, we’ve begun to chip away at the task and make real progress, even as we’re still a long way from our ultimate API goals. I hope our experience resonates with others and serves as inspiration for those who are just beginning your API journey!
 Our API Program is growing up so fast! (https://developer.ipums.org)
Our API Program is growing up so fast! (https://developer.ipums.org)
Authored by Fran Fabrizio
Code · APIs
IPUMS NHGIS