Up to this point, this blog has used static maps to visualize new datasets and raster processing techniques. Single-image maps like these are often the best choice when presenting specific findings or patterns because you can focus attention on the most important details of your work.
However, there are cases when it can be useful to view your data interactively. For instance, interactive maps can allow you to:
- Familiarize yourself with a new spatial data source
- Identify outliers or potential data quality issues
- Generate new research hypotheses based on visible patterns
- Visualize variables with wide distributions or spatial regions with significant variability in size, which may be difficult to display on a single static map
In this post and the next, we’ll demonstrate how to build an interactive map to display the population density distribution in Ethiopia. Using data from the Global Human Settlement Layer (GHSL) and the leaflet package in R, we’ll build an interactive map that we can use to explore and compare population density at two different time points. Finally, we’ll add DHS survey data to consider how the IPUMS DHS URBAN variable compares to the density estimates we get from the GHSL.

© Vladimir Agafonkin (BSD 2-Clause)
This post will focus on how to access GHSL data and build the foundations of a leaflet map. Then, in our next post, we’ll dive into more detailed map options, including color palettes, layer toggling, and more.
First, we’ll load some of the packages we’ll be using. The leaflet package is the going to be our main focus for this post:
Measuring population density
There are several approaches to measuring population density across the Earth’s surface. Many of them incorporate inputs both from satellite measurements (e.g. of land surface type) as well as survey data (e.g. from local censuses) to estimate the density of people in a given area. We summarized several of the main population distribution data sources in our previous post, so take a look there for an overview.
It’s important to note that like many remotely-sensed data sources, these metrics represent estimates of population density in a given area. Thus, the values we see are a result of a spatial model, and don’t necessarily represent an explicit measurement of population in a given area, like a census.
Global Human Settlement Layer
We’ll use data from the Global Human Settlement Layer (GHSL), which provides several data sources for measuring human presence on the planet.
In particular, we’ll use GHS-SMOD, which combines two other GHSL products: GHS-BUILT-S, which estimates the presence of built-up surfaces, and GHS-POP, which estimates population distribution.
You can find more detailed information about the methodologies used to produce the GHSL in our previous post and on the GHSL website.
Obtaining GHS-SMOD data
You can download GHS-SMOD data for free from the GHSL website.
GHS-SMOD data is distributed for specific epochs (in 5-year increments) and tiles, similar to the NDVI data we used in previous posts. The GHSL interface provides you with an interactive map where you can point and click on the tiles you want to download:
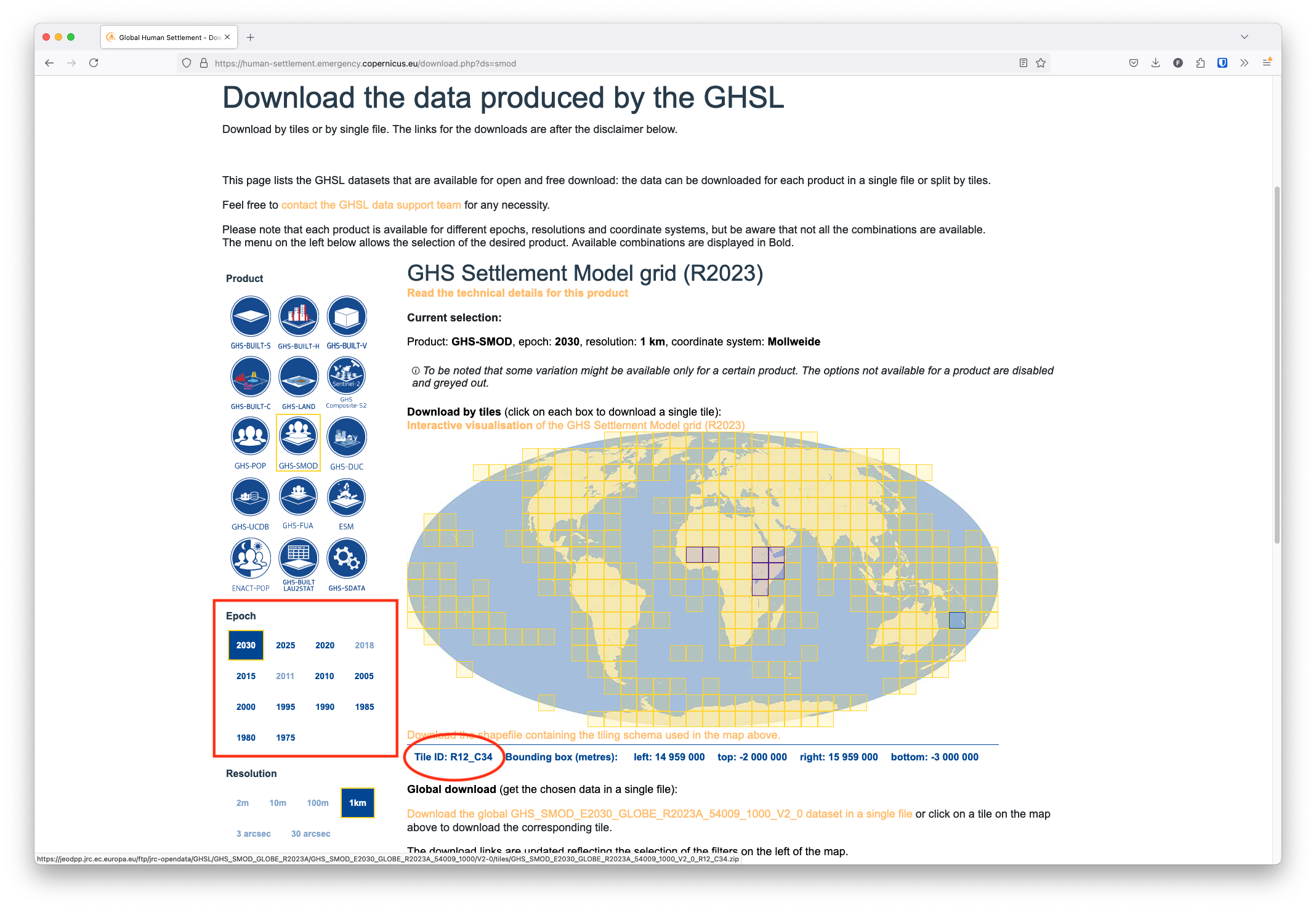
In this post, we’re focusing on Ethiopia. To obtain data for the entirety of the country, we’ll need to download 4 separate tiles with the following IDs:
- R8_C22
- R9_C22
- R8_C23
- R9_C23
You can see the tile IDs in the bottom left corner of the tile map as you hover over individual tiles on the world map (see the red oval in the image above).
We’ll download data for 2010 and 2020. You can do so by selecting these years in the Epoch selection grid on the left side of the screen (see the red square in the image above) and clicking on the same tiles again.
Clicking the tiles will download a .zip archive containing the GHS-SMOD data for the selected tile and epoch. We’ve extracted the files within each of the 4 .zip archives and placed them in the data directory of our project. This produces a set of directories (with names like GHS_SMOD_E2020_GLOBE_R2023A_54009_1000_V2_0_R8_C22) containing .tif files that hold the actual raster data for each tile and epoch.
Loading GHS-SMOD data
We could load each .tif file individually with rast(), but because we have several files with similar naming patterns, we can identify the relevant files in our data directory more efficiently by listing them with list.files().
Here, we use the pattern argument to specify that we only want to list files that match the text "GHS_SMOD_E2010" (for the 2010 epoch) and have the tif extension.
We’ve also set recursive = TRUE to list all files (even within subdirectories of the data directory) and full.names = TRUE to produce the full file path for each file:
ghs_smod_2010 <- list.files(
"data",
pattern = "GHS_SMOD_E2010.+tif$",
recursive = TRUE,
full.names = TRUE
)
ghs_smod_2010
#> [1] "data/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R8_C22/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R8_C22.tif"
#> [2] "data/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R8_C23/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R8_C23.tif"
#> [3] "data/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R9_C22/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R9_C22.tif"
#> [4] "data/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R9_C23/GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R9_C23.tif"We’re use a regular expression to create the text-matching pattern for these files. We’ve introduced regular expressions previously, so take a look there if this is unfamiliar.
In this case, the .+ pattern matches any sequence of characters between the GHS_SMOD_E2010 text and the tif text. The $ pattern indicates that we want the tif text to appear at the very end of the file name.
If you’re not comfortable with regular expressions, you can always manually write out the file paths for the files you want to load.
We can do the same for our 2020 files. All we need to do is change the match pattern to include E2020 instead of E2010:
ghs_smod_2020 <- list.files(
"data",
pattern = "GHS_SMOD_E2020.+tif$",
recursive = TRUE,
full.names = TRUE
)The next steps follow closely with the workflow we introduced for tiled NDVI data: first, we’ll use the purrr package to iterate over each file path input and load it into its own raster with rast():
This produces a list of rasters for each of 2010 and 2020. For instance, the ghs_smod_2010 variable stores 4 rasters, each of which contains a different spatial area (tile) for the 2010 epoch.
To combine the tiles for each epoch, we need to mosaic the tiles together. We can do so with mosaic() from terra, as we’ve shown before. Since we have multiple tiles to combine, we can iteratively mosaic them with reduce() from the purrr package. This takes each raster in the list and combines it with the others one-by-one using the supplied function (in this case, mosaic()).
At this point, we have two rasters for the full spatial extent of Ethiopia, one for each epoch. We can combine them with the familiar c() function so each epoch is represented in a single raster layer in the same raster stack.
ghs_smod <- c(ghs_smod_2010, ghs_smod_2020)Now we finally have a single raster data source for the entirety of Ethiopia with 2 layers: one for 2010 and one for 2020.
ghs_smod
#> class : SpatRaster
#> size : 2000, 2000, 2 (nrow, ncol, nlyr)
#> resolution : 1000, 1000 (x, y)
#> extent : 2959000, 4959000, 0, 2e+06 (xmin, xmax, ymin, ymax)
#> coord. ref. : World_Mollweide
#> source(s) : memory
#> varnames : GHS_SMOD_E2010_GLOBE_R2023A_54009_1000_V2_0_R8_C22
#> GHS_SMOD_E2020_GLOBE_R2023A_54009_1000_V2_0_R8_C22
#> names : GHS_SMOD_E2010_~000_V2_0_R8_C22, GHS_SMOD_E2020_~000_V2_0_R8_C22
#> min values : 10, 10
#> max values : 30, 30Categorical rasters
GHS-SMOD is in raster format, but it’s different than some of the other rasters we’ve considered up to this point. Rather than being a continuous measure of population density, it provides a set of density categories. Each pixel in the raster will have a single numeric value, but these values correspond to particular categories:
| Code | Density Category |
|---|---|
| 10 | Water |
| 11 | Very low |
| 12 | Low |
| 13 | Rural |
| 21 | Suburban |
| 22 | Semi-dense urban |
| 23 | Dense urban |
| 30 | Urban center |
If we examine all the unique values in the raster, we notice they all fall neatly into one of these categories:
as.numeric(unique(values(ghs_smod[[1]])))
#> [1] 11 12 13 10 21 23 22 30However, because the raster values are still encoded as numbers, our ghs_smod object currently has no indication that its values should be treated as categories rather than continuous numeric values.
To indicate the categorical nature of our raster, we can set the levels() of the raster using terra. We’ll make a data.frame that contains a mapping of the numeric values and their associated density categories:
density_lvls <- data.frame(
id = c(10, 11, 12, 13, 21, 22, 23, 30),
urban = c(
"Water", "Very low", "Low", "Rural", "Suburban",
"Semi-dense urban", "Dense urban", "Urban center"
)
)
density_lvls
#> id urban
#> 1 10 Water
#> 2 11 Very low
#> 3 12 Low
#> 4 13 Rural
#> 5 21 Suburban
#> 6 22 Semi-dense urban
#> 7 23 Dense urban
#> 8 30 Urban centerThen, we can assign these levels to our raster layers with the levels() function:
Each layer (i.e. epoch) needs to be assigned levels individually. For raster stacks containing more epochs, you may want to do this iteratively. Since we are only using two epochs, we’ll simply assign levels manually for each layer.
Now, we can confirm that our raster layers are indeed categorical with is.factor():
is.factor(ghs_smod)
#> [1] TRUE TRUEExplicitly converting our raster to categorical format will come in handy later when we project our rasters to be compatible with our interactive maps.
An introduction to Leaflet
We’ll use the leaflet package to produce our maps for this post. The leaflet package provides an R interface with the leaflet.js JavaScript library. While not all of the functionality available in the JavaScript version is available in R, the package makes it surprisingly easy to quickly assemble professional-quality interactive maps for data exploration and presentation.
You’ll find that Leaflet maps are built in layers, similar to how you would build a ggplot2 chart, making the learning curve a little bit easier.
Basemaps
Leaflet comes with several built in basemaps, or background layers that show common geographic boundaries to help orient a viewer to the map.
To make a new Leaflet map, first use the leaflet() function. On its own, this doesn’t add anything to our map, but we can add a basemap with the addProviderTiles() function. We’re going to use the Dark Matter basemap tiles from CartoDB.
To see all the available basemap providers, use leaflet::providers.
The setView() function allows us to specify the centerpoint and initial zoom level of the map:
leaflet() |>
addProviderTiles("CartoDB.DarkMatterNoLabels") |>
setView(lng = 10, lat = 40, zoom = 2)Dark maps should be deployed with care, as they occasionally become difficult to read. In this case, we’ll plot our density data as if it were “lighting up” on top of the background, so a dark basemap should work well. This visual nod to city lights will hopefully help reinforce the subject matter of the map. Note that we’re not actually displaying a map of light sources themselves, though!
As you can see, we already have an interactive map of the world! We’ll go ahead and save this basemap in an R variable so we don’t have to rewrite this code. We’ll also update our view parameters to set the default map view to be centered on Ethiopia, since this will be our area of interest:
basemap <- leaflet() |>
addProviderTiles("CartoDB.DarkMatterNoLabels") |>
setView(lng = 40.81, lat = 8.23, zoom = 6)Adding data layers
Of course, we ultimately want to map our own data, not just a prepackaged basemap.
Adding data to a map is as simple as adding more layers, but we’ll need to consider what type of data we’re adding, as this will affect what type of geometry layer we use (this is similar to the different geom_ layer options in ggplot2). You can see the most common types of layers by looking at the help for ?addControl.
In our case, our ghs_smod data is in raster format, so we’ll want to use addRasterImage(). All we need to do is provide our data to the map layer (we’ll only plot the 2010 data for now):
basemap |>
addRasterImage(ghs_smod[[1]])Coordinate reference systems
You may notice that the raster above appears a bit warped on the edges, despite the fact that the GHSL download page showed square tiles. Before we forge ahead, it’s worth considering our data’s coordinate reference system (CRS) to make sure we understand why this is happening.
We’ve covered reference systems and projections in a previous post, so check that out if you need a refresher.
Web Mercator
Leaflet uses a CRS known as Web Mercator in its maps. Web Mercator (EPSG:3857) is a modified form of the common Mercator projection and was designed to improve processing speeds for web-based maps. Many web-based mapping applications therefore use Web Mercator by default.
Accordingly, leaflet will automatically project our data to Web Mercator. So, even though our GHS data is in a Mollweide projection, leaflet displays the raster in Web Mercator. This is why the raster boundaries appear distorted from what we may have expected based on the GHSL website.
If we turn off this default behavior, we’ll notice the discrepancy in our data and basemap (which is also in Web Mercator). See how the coastlines in the Red Sea appear offset between the raster and the basemap if we don’t project our data:
basemap |>
setView(lat = 15.5, lng = 41.89, zoom = 7) |>
addRasterImage(
ghs_smod[[1]],
project = FALSE, # Suppress automatic projection
opacity = 0.6
)Raster reprojection
While leaflet is willing to do this transformation for us, it’s often better to explicitly transform our data to the correct CRS to ensure that any other spatial operations we do to our rasters work as expected. We can do so by using project() with the EPSG code for Web Mercator
ghs_smod <- project(ghs_smod, "epsg:3857")As we’ve mentioned before, it’s typically best to avoid projecting raster data when possible because doing so requires that the raster values be resampled, introducing uncertainty into the data.
Because our goal here is visualization, we don’t need to be as concerned about the loss of precision in our data for these maps. If we were using these data for spatial analysis, we would want to be more careful to find a CRS that would minimize distortion in our region of interest.
Categorical raster present an additional challenge when projecting because each cell must belong to a single category.
Fortunately, because we’ve made sure that our ghs_smod raster is represented as a categorical raster, project() will automatically use a raster resampling method that preserves this property.
However, if the input raster were still in numeric format, resampling would likely produce some intermediate cell values that would no longer belong to one of the density categories provided by the GHS!
Up next
We’ve now completed the primary data preparation steps! We’ve managed to
- Download GHS-SMOD data for Ethiopia
- Load and organize our raster data into a single raster stack
- Convert our raster data to categorical format
- Project our raster to the CRS expected by leaflet
In our next post, we’ll focus more on the aesthetic options available when producing leaflet maps. We’ll discuss color palettes, additional layer types, legends, and some basic interactivity!
Getting Help
Questions or comments? Check out the IPUMS User Forum or reach out to IPUMS User Support at ipums@umn.edu.